Sheng-Chieh Lin and Jimmy Lin - Densifying Sparse Representations for Passage Retrieval by Representational Slicing (arXiv 2021)
#DSRs #解説
Densify Sparse Representations
Sheng-Chieh Lin, Jimmy Lin - Densifying Sparse Representations for Passage Retrieval by Representational Slicing (2020) [arXiv]
Learned sparse and dense representations capture different successful approaches to text retrieval and the fusion of their results has proven to be more effective and robust. Prior work combines dense and sparse retrievers by fusing their model scores. As an alternative, this paper presents a simple approach to densifying sparse representations for text retrieval that does not involve any training. Our densified sparse representations (DSRs) are interpretable and can be easily combined with dense representations for end-to-end retrieval. We demonstrate that our approach can jointly learn sparse and dense representations within a single model and then combine them for dense retrieval. Experimental results suggest that combining our DSRs and dense representations yields a balanced tradeoff between effectiveness and efficiency.
TL;DR
- https://github.com/smiyawaki0820/aio2-tfidf-baseline/tree/main/densifiers
- NOTE: 上記のコードは著者らによる実装ではないため、誤っている場合があるかもしれません。
どんなもの?
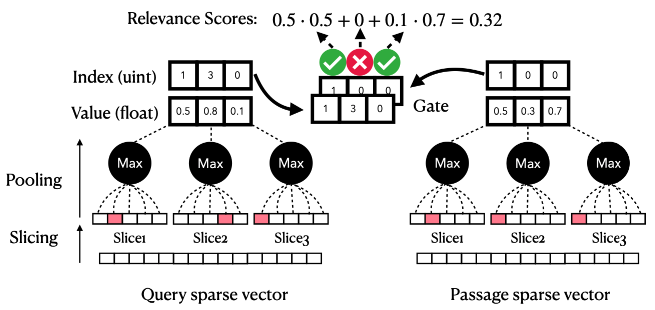
- スライシングによって疎表現(TF-IDF や SPLADE)を高密度化するアプローチを提案。
- 学習は不要で、クエリと文書間の関連度を計算するためにゲート内積 (GIP) 演算を提案。
- DSR と他の密表現を組み合わせることも可能。
先行研究と比べてどこがすごい?
- TF-IDF などは、特に大規模な文書に適用すると vocabulary size が大きくなるため計算量が大きい。また contextualized sparse representations (UniCOIL や SPLADE など) は、言語モデルの語彙数に等しい。
技術や手法のキモはどこ?
- TF-IDF など
語彙数 == 次元数の場合に適用可能 - 疎なベクトル表現はスライス毎に分割しても、スライス内に大きな値を持つ語彙が数個しか存在しないためスライス毎に max pooling を適用することで次元数を削減
- クエリと文書の対応するスライス間で語彙数が一致する場合に内積を計算する Gated Inner Product (GIP) を提案
- さらに計算量を減らすため、retrieval-rerank の二段階で検索対象を限定する。retrieval では各スライスに対して閾値の通過を判定することで、値が低い(情報量が低い)単語を内積計算の対象から除外する。
どうやって有効だと検証した?

議論はある?
- メモリ効率が大幅に減少できるのは良い
- スライス毎に一つの注目単語(TF-IDF など値が高くなる場合)は効果が期待できるが、スライス内に注目単語が二つ以上存在する場合は max pooling によりどちらか一つが選択されてしまう
- 逆に TF-IDF でノイズとなりうる false negative 単語については計算対象から除外される可能性がある
- スライスの方法は複数考えられるため、語彙毎の出現頻度の重みなどを使用すればより良いスライス方法が考えられるかもしれない
次に読むべき論文は?
- Dai+'20 - Context-Aware Sentence/Passage Term Importance Estimation For First Stage Retrieval [arXiv][GitHub]
- Mallia+'21 - Learning Passage Impacts for Inverted Indexes (SIGIR) [arXiv][GitHub]
- Lin+'21 - A Few Brief Notes on DeepImpact, COIL, and a Conceptual Framework for Information Retrieval Techniques [arXiv]
- Formal+'21 - SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking (SIGIR) [arXiv][GitHub]
- Formal+'21 - SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval [arXiv]