NAACL2022 - pickup
https://2022.naacl.org/program/accepted_papers/
Entity
NER
- Wu+'22 - Robust Self-Augmentation for Named Entity Recognition with Meta Reweighting (NAACL) [arXiv]
- Fetahu+'22 - Dynamic Gazetteer Integration in Multilingual Models for Cross-Lingual and Cross-Domain Named Entity Recognition (NAACL) [AmazonScience]
- Wang+'22 - Sentence-Level Resampling for Named Entity Recognition (NAACL) [openreview]
- Hu+'22 - Hero-Gang Neural Model For Named Entity Recognition (NAACL) [arXiv]
- Pasad+'22 - On the Use of External Data for Spoken Named Entity Recognition (NAACL) [arXiv]
- Ying+'22 - Label Refinement via Contrastive Learning for Distantly-Supervised Named Entity Recognition (NAACL)
- Gu+'22 - Delving Deep into Regularity: A Simple but Effective Method for Chinese Named Entity Recognition (NAACL) [arXiv]
- Shao+'22 - Low-resource Entity Set Expansion: A Comprehensive Study on User-generated Text (NAACL) [acsweb]
- Tedeschi+'22 - MultiNER: A Multilingual, Multi-Genre and Fine-Grained Dataset for Named Entity Recognition (NAACL)
- Shrimal+'22 - NER-MQMRC: Formulating Named Entity Recognition as Multi Question Machine Reading Comprehension (NAACL) [arXiv]
Relation
- Agarwal+'22 - Entity Linking via Explicit Mention-Mention Coreference Modeling (NAACL) [openreview]
- Wang+'22 - Should We Rely on Entity Mentions for Relation Extraction? Debiasing Relation Extraction with Counterfactual Analysis (NAACL) [arXiv]
- Hakami+'22 - Learning to Borrow– Relation Representation for Without-Mention Entity-Pairs for Knowledge Graph Completion (NAACL) [arXiv]
- Xu+'22 - Modeling Explicit Task Interactions in Document-Level Joint Entity and Relation Extraction (NAACL) [arXiv]
- Yuan+'22 - Generative Biomedical Entity Linking via Knowledge Base-Guided Pre-training and Synonyms-Aware Fine-tuning (NAACL) [arXiv]
- Chai+'22 - Incorporating Centering Theory into Entity Coreference Resolution (NAACL)
- Yu+'22 - Relation-Specific Attentions over Entity Mentions for Enhanced Document-Level Relation Extraction [arXiv]
- Bhargav+'22 - Zero-shot Entity Linking with Less Data (NAACL) [arXiv]
- Liu+'22 - Dangling-Aware Entity Alignment with Mixed High-Order Proximities (NAACL) [arXiv]
- Ayoola+'22 - ReFinED: An Efficient Zero-shot-capable Approach to End-to-End Entity Linking (NAACL) [AmazonScience]
- Laskar+'22 - BLINK with Elasticsearch for Efficient Entity Linking in Business Conversations (NAACL) [arXiv]
Embeddings, Robustness
- Nishikawa+'22 - EASE: Entity-Aware Contrastive Learning of Sentence Embedding (NAACL) [arXiv]
- Ayoola+'22 - Improving Entity Disambiguation by Reasoning over a Knowledge Base (NAACL) [AmazonScience]
- Yan+'22 - On the Robustness of Reading Comprehension Models to Entity Renaming (NAACL) [arXiv]
- Yamada+'22 - Global Entity Disambiguation with BERT [arXiv]
- Onoe+'22 - Entity Cloze By Date: Understanding what LMs know about unseen entities (NAACL) [arXiv]
Others
- Deeksha+'22 - Commonsense and Named Entity Aware Knowledge Grounded Dialogue Generation (NAACL) [arXiv]
- Schuster+'22 - When a sentence does not introduce a discourse entity, Transformer-based models still often refer to it (NAACL) [arXiv]
- Zhang+'22 - Improving the Faithfulness of Abstractive Summarization via Entity Coverage Control (NAACL)
Multi-Modal
- Wang+'22 - ITA: Image-Text Alignments for Multi-Modal Named Entity Recognition (NAACL) [arXiv]
- Chen+'22 - Good Visual Guidance Make A Better Extractor: Hierarchical Visual Prefix for Multimodal Entity and Relation Extraction (NAACL) [paperswithcode]
Sentiment Analysis
- Zhang+'22 - SSEGCN: Syntactic and Semantic Enhanced Graph Convolutional Network for Aspect-based Sentiment Analysis (NAACL) [[ar
- Toledo-Ronen+'22 - Multi-Domain Targeted Sentiment Analysis (NAACL) [arXiv]
- Cao+'22 - Aspect Is Not You Need: No-aspect Differential Sentiment Framework for Aspect-based Sentiment Analysis (NAACL)
- Mireshghallah+'22 - UserIdentifier: Implicit User Representations for Simple and Effective Personalized Sentiment Analysis (NAACL) [arXiv]
- Liu+'22 - A Robustly Optimized BMRC for Aspect Sentiment Triplet Extraction (NAACL) [[arXiv]
- Liu+'22 - A Dual-Channel Framework for Sarcasm Recognition by Detecting Sentiment Conflict (NAACL) [arXiv]
- Hosseini-Asl+'22 - A Generative Language Model for Few-shot Aspect-Based Sentiment Analysis (NAACL) [arXiv]
- Ahbali+'22 - Identifying Corporate Credit Risk Sentiments from Financial News (NAACL) [openreview]
Multi-Modal
- Hazarika+'22 - Analyzing Modality Robustness in Multimodal Sentiment Analysis (NAACL) [arXiv]
- Li+'22 - CLMLF:A Contrastive Learning and Multi-Layer Fusion Method for Multimodal Sentiment Detection (NAACL) [arXiv]
Question Answering
QA
- Pang+'22 - QuALITY: Question Answering with Long Input Texts, Yes! (NAACL) [arXiv]
- Sun+'22 - JointLK: Joint Reasoning with Language Models and Knowledge Graphs for Commonsense Question Answering (NAACL) [arXiv]
- Zhao+'22 - Compositional Task-Oriented Parsing as Abstractive Question Answering (NAACL) [arXiv]
- Zhou+'22 - Consolidating Answers in Question Answering Systems (NAACL) [arXiv]
- Zhong+'22 - ProQA: Structural Prompt-based Pre-training for Unified Question Answering (NAACL) [arXiv]
- Wang+'22 - Modeling Exemplification in Long-form Question Answering via Retrieval (NAACL) [arXiv]
- Lee+'22 - CS1QA: A Dataset for Code-based Question Answering in an Introductory Programming Course (NAACL)
- Li+'22 - MultiSpanQA: A Dataset for Multi-Span Question Answering (NAACL)
- Caciularu+'22 - Question-Evidence Similarity Learning for Long-Context Question Answering (NAACL)
- Wang+'22 - Towards Process-Oriented, Modular, and Versatile Question Generation that Meets Educational Needs (NAACL) [arXiv]
- Huber+'22 - CCQA: A New Web-Scale Question Answering Dataset for Model Pre-Training (NAACL) [arXiv]
- Zhu+'22 - Unsupervised Domain Adaptation for Question Generation with DomainData Selection and Self-training (NAACL)
- Limkonchotiwat+'22 - CL-ReLKT: Cross-lingual Language Knowledge Transfer for Multilingual Retrieval Question Answering (NAACL) [openreview]
- Qian+'22 - Capturing Conversational Interaction for Question Answering via Global History Reasoning (NAACL)
- Liu+'22 - Challenges in Generalization in Open Domain Question Answering (NAACL) [arXiv]
- Kim+'22 - Exploiting Numerical-Contextual Knowledge to Improve Numerical Reasoning in Question Answering (NAACL)
Reading Comprehension
- Zhao+'22 - TIE: Topological Information Enhanced Structural Reading Comprehension on Web Pages (NAACL) [arXiv]
- Yan+'22 - On the Robustness of Reading Comprehension Models to Entity Renaming (NAACL) [arXiv]
- Hao+'22 - Understand before Answer: Improve Temporal Reading Comprehension via Precise Question Understanding (NAACL) [openreview]
- Mingye+'22 - Cooperative Self-training of Machine Reading Comprehension (NAACL) [openreview]
- Wu+'22 - Continual Machine Reading Comprehension via Uncertainty-aware Fixed Memory and Adversarial Domain Adaptation [arXiv]
- Ji+'22 - To Answer or Not To Answer? Improving Machine Reading Comprehension Model with Span-based Contrastive Learning
- Shrimal+'22 - NER-MQMRC: Formulating Named Entity Recognition as Multi Question Machine Reading Comprehension (NAACL) [arXiv]
- Oguz+'22 - UniK-QA: Unified Representations of Structured and Unstructured Knowledge for Open-Domain Question Answering (NAACL) [arXiv]
- Murakhovs'ka+'22 - MixQG: Neural Question Generation with Mixed Answer Types (NAACL) [arXiv]
- Qi+'22 - All Information is Valuable: Question Matching over Full Information Transmission Network (NAACL)
- Liu+'22 - Seeing the wood for the trees: a contrastive regularization method for the low-resource Knowledge Base Question Answering
- Dutt+'22 - PerKGQA: Question Answering over Personalized Knowledge Graphs (NAACL) [AmazonScience]
- Feng+'22 - Multi-Hop Open-Domain Question Answering over Structured andUnstructured Knowledge (NAACL)
- Laban+'22 - Quiz Design Task: Helping Teachers Create Quizzes with Automated Question Generation (NAACL) [arXiv]
- Mitra+'22 - Constraint-based Multi-hop Question Answering with Knowledge Graph (NAACL)
Table
- Jiang+'22 - OmniTab: Pretraining with Natural and Synthetic Data for Few-shot Table-based Question Answering (NAACL)
- Zhang+'22 - Crake: Causal-Enhanced Table-Filler for Question Answering over Large Scale Knowledge Base
- Katsis+'22 - AIT-QA: Question Answering Dataset over Complex Tables in the Airline Industry (NAACL) [arXiv]
SQL
Multi-Modal
- Mao+'22 - Dynamic Multistep Reasoning based on Video Scene Graph for Video Question Answering (NAACL)
- Vedd+'22 - Guiding Visual Question Generation (NAACL) [arXiv]
- You+'22 - End-to-end Spoken Conversational Question Answering: Task, Dataset and Model (NAACL) [arXiv]
Retrieval
- Santhanam+'22 - Maize: Effective and Efficient Retrieval via Lightweight Late Interaction (NAACL) [arXiv]
- Wang+'22 - GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval (NAACL) [arXiv]
- Wang+'22 - Modeling Exemplification in Long-form Question Answering via Retrieval (NAACL) [arXiv]
- Kim+'22 - Collective Self-Labeling for Passage Retrieval (NAACL) [arXiv]
- Shi+'22 - Improving Neural Models for Radiology Report Retrieval with Lexicon-based Automated Annotation (NAACL) [research.ibm]
- Limkonchotiwat+'22 - CL-ReLKT: Cross-lingual Language Knowledge Transfer for Multilingual Retrieval Question Answering (NAACL) [openreview]
- Oguz+'22 - Domain-matched Pre-training Tasks for Dense Retrieval (NAACL) [arXiv]
- Gao+'22 - Retrieval-Augmented Multilingual Keyphrase Generation with Retriever-Generator Iterative Training (NAACL) [arXiv]
- Ribeiro+'22 - Entailment Tree Explanations via Iterative Retrieval-Generation Reasoner (NAACL) [arXiv]
- Biswas+'22 - Retrieval Based Response Letter Generation For a Customer Care Setting (NAACL)
- Wan+'22 - Fast and Light-Weight Answer Text Retrieval in Dialogue Systems (NAACL) [zhuanzhi]
ITR
- Ren+'22 - Leaner and Faster: Two-Stage Model Compression for Lightweight Text-Image Retrieval (NAACL) [arXiv]
- Fan+'22 - Negative Sample is Negative in Its Own Way: Tailoring Negative Sentences for Image-Text Retrieval (NAACL) [semanticsholar]
- Liu+'22 - Cross-Lingual Cross-Modal Consolidation for Effective Multilingual Video Corpus Moment Retrieval (NAACL)
Active Learning
SMALL-TEXT: テキスト分類における Active Learning
- 本ページの目的
- Active Learning (Pool-based Sampling)
- SMALL-TEXT
- 最後に
本ページの目的
本ページは、2022.06.13 に ver1.0.0 がリリースされました、能動学習(Active Learning)のフレームワークである SMALL-TEXT について紹介します。
なお、著者は Active Learning について勉強中ですので、誤った表記などありましたらコメント等で教えていただけますと幸いです。
著者のメモとしての概要紹介のため、内容を一部省略しています。 詳細については 公式ドキュメント を参照下さい。
Active Learning (Pool-based Sampling)
本題に入る前に、SMALL-TEXT で採用されている Pool-based Sampling による Active Leraning の概要について説明します。
ドメインが限定されている開発やテキスト分析業務などでは、注釈付きデータが存在しないために教師あり学習の手法を試すことができない(大量のテキストデータに対してアノテーションを行わなければならない)場面が多々あります。
そこで Active Learning における Pool-based Sampling では、以下のような繰り返しを行うことで、注釈コストを抑えつつ、高性能な機械学習モデルを学習するための枠組みを提供します(下図):
- 小規模な注釈付きデータセットを作成(データの初期選択)
- 作成したデータセットを用いてモデルを学習
- 学習したモデルを用いて注釈が付いていない生データに対して予測
- 予測結果に基づいてモデルの学習に有効であると判断されたデータを選択(データ選択)
- 選択されたデータを学習データに追加して、十分な性能が出るまで 2. から繰り返す(停止条件)

Pool-based Sampling の他にも、Stream-based Selective Sampling や Membership Query Synthesis などのアプローチが提案されています(以下に列挙したものを参照下さい)。
参考
- https://small-text.readthedocs.io/en/latest/active_learning.html
- Settles+'10 - Active Learning Literature Survey [paper]
- Pardakhti+'21 - Practical Active Learning with Model Selection for Small Data (ICML) [paper]
- Active Learning: A Practical Approach to Improve Your Data Labeling Experience - Towards Data Science
- 画像データに対するActive learningの現状と今後の展望 ~最新の教師なし学習を添えて~ - ABEJA Tech Blog
- 系列ラベリングにおけるActive Learning - Fintan
- 鈴木健史氏 (FastLabel) - Active Learning for Auto Annotation - Machine Learning Casual Talks #13 (Online)
SMALL-TEXT
SMALL-TEXT は、自然言語処理のテキスト分類タスクを対象分野とした Active Learning のフレームワークを提供する Python パッケージです。 MIT ライセンスによる使用が可能で、現在は、バイナリ・マルチクラス分類タスクをサポートしています。
- github.com/webis-de/small-text
- small-text.readthedocs.io
- Schröder+'21 - Small-Text: Active Learning for Text Classification in Python (arXiv)


クイックスタート
# pip install small-text pip install small-text[transformers]
SMALL-TEXT では、サンプルコードとして二つのノートブックが公開されています:
- Intro: Active Learning for Text Classification with Small-Text
- Using Stopping Criteria for Active Learning
PoolBasedActiveLearner [doc] [code]
前述の通り、SMALL-TEXT では Pool-based Sampling を採用しています。 PoolBasedActiveLearner では、利用可能な全てのデータをプールに格納し、学習を行うことで注釈済みデータを更新します。
# https://github.com/webis-de/small-text/blob/v1.0.0/small_text/active_learner.py#L63 # 一部省略。詳細はソースコードを参照されたい。 class PoolBasedActiveLearner(AbstractPoolBasedActiveLearner): def __init__(self, clf_factory, query_strategy, dataset, ...): self.dataset = dataset # 注釈対象のデータセット self._clf_factory = clf_factory # 分類器 self._query_strategy = query_strategy # データ選択方法 self.indices_labeled = np.empty(shape=0, dtype=int) # 注釈付与済み self.indices_ignored = np.empty(shape=0, dtype=int) def initialize_data(self, indices_initial, y_initial, ...): """ 初期データの登録 >>> from small_text.initialization import random_initialization >>> indices_initial = random_initialization(y_train, n_samples=100) >>> active_learner.initialize_data(indices_initial, y_train[indices_initial]) """ # データの初期化 self.indices_labeled = indices_initial self.y = y_initial # 分類器の学習 self._retrain(indices_validation=indices_validation) def query(self, num_samples, ...) -> numpy.ndarray[int]: """ 次に注釈対象とするデータを選択する >>> indices_queried = active_learner.query(num_samples=100) """ self.indices_queried = self.query_strategy.query(...) return self.indices_queried def update(self, y, ...): """ 注釈されたデータを indices_labeled に格納し、分類器を再学習する >>> # active_learner.query で取得した indices_queried に対する注釈を入力 >>> y = train_data.y[indices_queried] # 正解データとする場合 >>> active_learner.update(y) """ # データの更新 self.indices_labeled = np.concatenate([self.indices_labeled, self.indices_queried[~ignored]]) self.y = concatenate(self.y, y) # 分類器の学習 self._retrain(indices_validation=indices_validation) def _retrain(self, indices_validation=None): """ classifier の学習 """ if self._clf is None or not self.reuse_model: if hasattr(self, '_clf'): del self._clf self._clf = self._clf_factory.new() dataset = self.dataset[self.indices_labeled].clone() dataset.y = self.y indices = np.arange(self.indices_labeled.shape[0]) mask = np.isin(indices, indices_validation) train = dataset[indices[~mask]] valid = dataset[indices[mask]] self._clf.fit(train, validation_set=valid)
データの初期選択 / Initialization Strategy [doc] [code]
学習データセットを初め(iteration = 0)に用意するための戦略が定義されます。
random_initialization()[source]- 入力データからランダムにサンプルしたデータを返します。
random_initialization_stratified()[source]- ラベル分布が均等になるように入力データをサンプルします。
e.g. random_initialization
def random_initialization(x, n_samples=10): return np.random.choice( list_length(x), size=n_samples, replace=False )
注釈対象データの選択 / Query Strategies [doc] [code]
学習セットに追加する(学習に有効だと考えられる)データを選択するための戦略が定義されます。 各手法の詳細については論文を参照下さい(まとめたものを更新予定)。
LeastConfidence(Lewis+'94)PredictionEntropy(Holub+'08)BreakingTies(Luo+'05)EmbeddingKMeans(Yuan+'20)GreedyCoresetLightweightCoresetContrastiveActiveLearning(Margatina+'21)DiscriminativeActiveLearning(Gissin+'19)SEALS(Coleman+'21)ExpectedGradientLengthMaxWord(Zhang+'17)ExpectedGradientLengthLayer(Zhang+'17)BADGE(Ash+'19)
e.g. LeastConfidence
注釈なしのデータセットから、モデルの学習に有効であるサブセットを選択するための手法の一つに、 モデルの予測が困難なサブセットを選択する 不確実性サンプリング があります。

LeastConfidence は、不確実性のスコアを決定する手法の一つで、各インスタンスでの予測値が最大となるラベル集合に対して、最大予測値が小さい順にデータを選択します。
# https://github.com/webis-de/small-text/blob/v1.0.0/small_text/query_strategies/strategies.py # 一部省略。詳細はソースコードを参照されたい。 class LeastConfidence(ConfidenceBasedQueryStrategy): def __init__(self): super().__init__(lower_is_better=True) def get_confidence(self, clf, dataset, _indices_unlabeled, _indices_labeled, _y): proba = clf.predict_proba(dataset) return np.amax(proba, axis=1) # 予測が最大の中から...(lower_is_better = True) def __str__(self): return 'LeastConfidence()' class ConfidenceBasedQueryStrategy(QueryStrategy): def __init__(self, lower_is_better=False): self.lower_is_better = lower_is_better self.scores_ = None def query(self, clf, dataset, indices_unlabeled, indices_labeled, y, n=10): confidence = self.score(clf, dataset, indices_unlabeled, indices_labeled, y) # スコア算出 indices_partitioned = np.argpartition(confidence[indices_unlabeled], n)[:n] # スコアが高い n 件を抽出 return np.array([indices_unlabeled[i] for i in indices_partitioned]) def score(self, clf, dataset, indices_unlabeled, indices_labeled, y): confidence = self.get_confidence(clf, dataset, indices_unlabeled, indices_labeled, y) self.scores_ = confidence if not self.lower_is_better: confidence = -confidence # lower_is_better → 正負反転 return confidence @abstractmethod def get_confidence(self, clf, dataset, indices_unlabeled, indices_labeled, y): # ConfidenceBasedQueryStrategy を継承して使用する場合 `get_confidence` メソッドを定義する
停止条件 / Stopping Criterion [doc] [code]
ループにおける繰り返しにおける停止基準が定義されます。 各手法の詳細については論文を参照下さい(まとめたものを更新予定)。
データセットと分類モデル
SMALL-TEXT では scikit-learn / pytorch / transformers の各モデルを扱うために、独自のクラスを定義しています。
e.g. TransformersDataset の作成
import datasets from small_text.integrations.transformers.datasets import TransformersDataset def prepro(tokenizer, sub_set) -> TransformersDataset: data = [] for text, label in zip(sub_set["text"], sub_set["label"]): encoded_text = tokenizer.encode_plus(text, **kwargs_encode) instance = (encoded_text["input_ids"], encoded_text["attention_mask"], label) data.append(instance) return TransformersDataset(data) def main(): kwargs_encode = { "add_special_tokens": True, "padding": "max_length", "max_length": 128, "return_attention_mask": True, "return_tensors": "pt", "truncation": "longest_first", } # see ... https://huggingface.co/docs/datasets/loading # following jsonl files are composed of {"text": str, "label": int} data_files = { "train": "data/train.jsonl", "valid": "data/valid.jsonl", } dataset = datasets.load_dataset("json", data_files=data_files) tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-v2") train_data: TransformersDataset = prepro(tokenizer, dataset["train"]) valid_data: TransformersDataset = prepro(tokenizer, dataset["valid"])
e.g. TransformerBasedClassificationFactory
ActiveLeanrer が分類器を反復的に定義する(コンストラクタに何を渡すかの情報が必要である)ために Factory を使用します。 TransformerBasedClassification については、ソースコード を参照した方がよいと感じたため、そちらを参照下さい。
# https://github.com/webis-de/small-text/blob/v1.0.0/small_text/integrations/transformers/classifiers/factories.py class TransformerBasedClassificationFactory(AbstractClassifierFactory): def __init__(self, transformer_model, num_classes, kwargs={}): self.transformer_model = transformer_model self.num_classes = num_classes self.kwargs = kwargs def new(self): return TransformerBasedClassification( self.transformer_model, self.num_classes, **self.kwargs )
最後に
黒橋研(京大)が提供している 日本語SNLI(JSNLI)データセット に対して SMALL-TEXT を使用してみました。 各イテレーションでの更新データサイズを 100 とし、RandomSampling と LeastConfidence で比較しています(シード数は 1 です...)。 こちらの コード で公開しています。 参考になれば幸いです(誤った箇所がありましたらコメントいただけますと幸いです)。

Oguz+'22 - UniK-QA: Unified Representations of Structured and Unstructured Knowledge for Open-Domain Question Answering (NAACL-HLT)
1. どんなもの?
- オープンドメイン質問応答において、様々な知識ソース(テキスト、表、リスト、KB)を扱うための統合手法を提案。
- KBQA タスクで大幅な性能改善、NQ・WebQuestions で SoTA を達成。
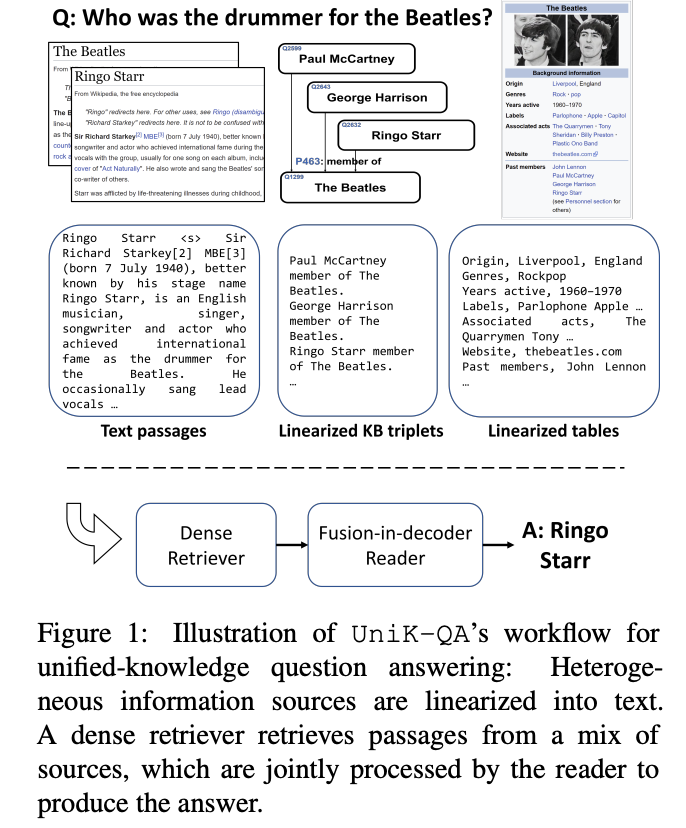
2. 先行研究と比べてどこがすごい?
- 先行研究では (1) 構造化知識ベースを用いた KBQA、および (2) テキストベースにおけるオープンドメイン質問応答タスク TextQA を別タスクとすることが一般的。テキストを知識グラフに組み込む手法 (Sun+'18; Lu+'19)も研究されているが、性能はあまり良くない。
- 本研究では、複数のサブシステムを保有したり、テキストを知識グラフに組み込んだりするのではなく、構造データをテキスト形式に変換することで構造化データを Transformer を用いた retriever-reader (DPR-FiD) 型システムで扱えるようにする。
- テキストやリストから構成される 27M の文書 + 456K の Wikipedia テーブル + Freebase および Wikidata から取得される 3B の知識ベース
3. 技術や手法のキモはどこ?
3.1. UniK-QA
- retriever-reader (DPR-FiD) システムを使用
- DPR 学習時は、Xiong+'21 のようにハード負例を学習ステップごとに選択する
- FiD では T5-large を用い、100 文書から解答を生成する
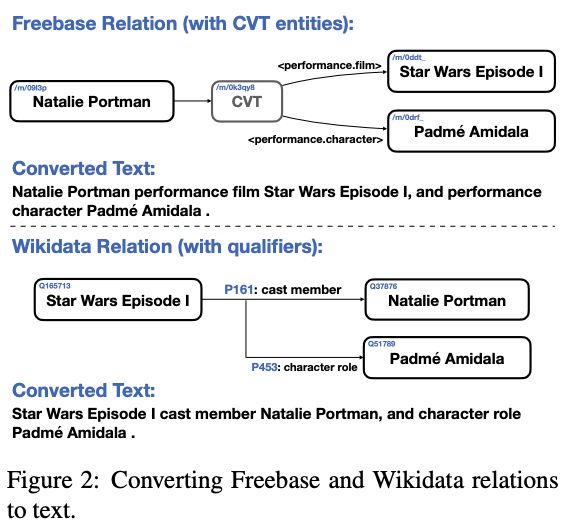
3.2. 知識ベースの統合
- RDF triple を
[subj] [pred] [obj]の形で変換するtemplate-based linearization:数十万種類の関係に対してテンプレートを用意するのは高コストmodel-based linearization:学習コストが加算 + 検索の再現性が低くなる
- 数十億単位の KB 全体をインデックス化することを回避するために、関係の検索を二段階で実装:
3.3. リスト・テーブルの統合
- リストについては、単にテキスト文書の一部として保持(することで検索性能が向上)
- テーブル(表+info-boxes)は NQ データが取得したものを使用し、入れ子テーブルは独立単位に抽出、また一行の表および
service表を除去。 - テーブルは以下二種類でテキスト化:
4. どうやって有効だと検証した?
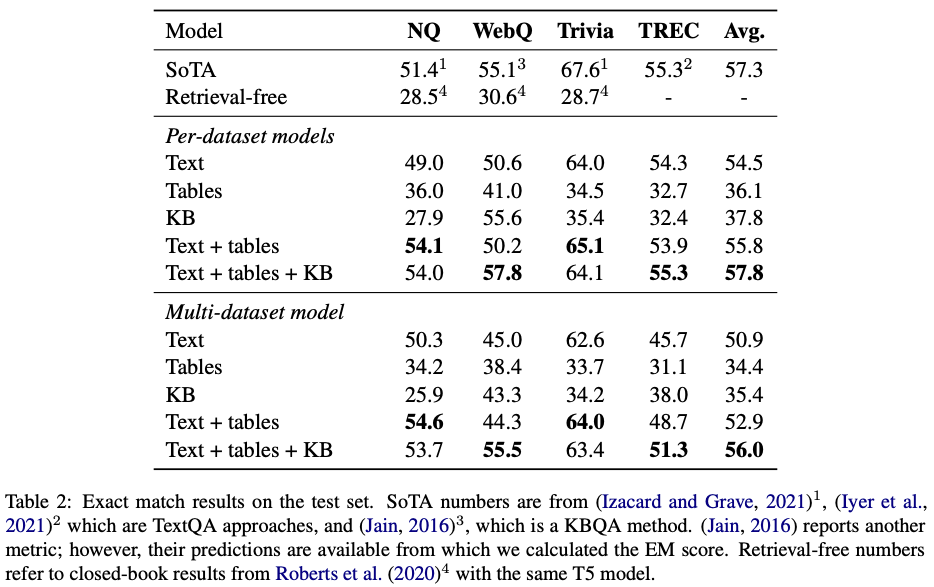
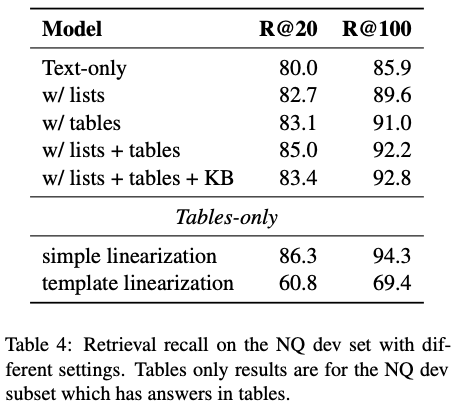
5. 議論はある?
6. 次に読むべき論文は?
ACL2022 ピックアップ - (NER, ABSA, QA)
https://www.2022.aclweb.org/papers
※ 分類漏れがある可能性があります。
Entity
NER
- Wang+'22 - MINER: Improving Out-of-Vocabulary Named Entity Recognition from an Information Theoretic Perspective (ACL) [arXiv]
- Ma+'22 - Decomposed Meta-Learning for Few-Shot Named Entity Recognition (ACL) [arXiv]
- Li+'22 - An Unsupervised Multiple-Task and Multiple-Teacher Model for Cross-lingual Named Entity Recognition (ACL)
- Yang+'22 - Bottom-Up Constituency Parsing and Nested Named Entity Recognition with Pointer Networks (ACL)
- Zhu+'22 - Boundary Smoothing for Named Entity Recognition (ACL)
- Snigdha+'22 - CONTaiNER: Few-Shot Named Entity Recognition via Contrastive Learning (ACL)
- Zhou+'22 - Distantly Supervised Named Entity Recognition via Confidence-Based Multi-Class Positive and Unlabeled Learning (ACL)
- Wang+'22 - Few-Shot Class-Incremental Learning for Named Entity Recognition (ACL)
- Chen+'22 - Few-shot Named Entity Recognition with Self-describing Networks (ACL)
- Lou+'22 - Nested Named Entity Recognition as Latent Lexicalized Constituency Parsing (ACL)
- Wan+'22 - Nested Named Entity Recognition with Span-level Graphs (ACL)
- Shen+'22 - Parallel Instance Query Network for Named Entity Recognition (ACL)
- Zheng+'22 - Cross-domain Named Entity Recognition via Graph Matching (ACL)
- Huang+'22 - Extract-Select: A Span Selection Framework for Nested Named Entity Recognition with Generative Adversarial Training (ACL)
- Yuan+'22 - Fusing Heterogeneous Factors with Triaffine Mechanism for Nested Named Entity Recognition (ACL)
- Ma+'22 - Label Semantics for Few Shot Named Entity Recognition (ACL)
- Xia+'22 - Learn and Review: Enhancing Continual Named Entity Recognition via Reviewing Synthetic Samples (ACL)
- Buaphet+'22 - Thai Nested Named Entity Recognition Corpus (ACL)
- Reich+'22 - Leveraging Expert Guided Adversarial Augmentation For Improving Generalization in Named Entity Recognition (ACL)
- Loukas+'22 - FiNER: Financial Numeric Entity Recognition for XBRL Tagging (ACL)
- Zhou+'22 - MELM: Data Augmentation with Masked Entity Language Modeling for Low-Resource NER (ACL)
- Ri+'22 - mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models (ACL)
- Leszczynski+'22 - TABi: Type-Aware Bi-Encoders for Open-Domain Entity Retrieval (ACL)
Entity Linking/Typing
- Galperin+'22 - Cross-Lingual UMLS Named Entity Linking using UMLS Dictionary Fine-Tuning (ACL)
- Han+'22 - Cross-Lingual Contrastive Learning for Fine-Grained Entity Typing for Low-Resource Languages (ACL)
- Pang+'22 - Divide and Denoise: Learning from Noisy Labels in Fine-Grained Entity Typing with Cluster-Wise Loss Correction (ACL)
- Chen+'22 - Learning from Sibling Mentions with Scalable Graph Inference in Fine-Grained Entity Typing (ACL)
- Wang+'22 - WikiDiverse: A Multimodal Entity Linking Dataset with Diversified Contextual Topics and Entity Types (ACL)
- Zaporojets+'22 - Towards Consistent Document-level Entity Linking: Joint Models for Entity Linking and Coreference Resolution (ACL)
- Sun+'22 - A Transformational Biencoder with In-Domain Negative Sampling for Zero-Shot Entity Linking (ACL)
- Mrini+'22 - Detection, Disambiguation, Re-ranking: Autoregressive Entity Linking as a Multi-Task Problem (ACL)
- Jin+'22 - How Can Cross-lingual Knowledge Contribute Better to Fine-Grained Entity Typing? (ACL)
- Lai+'22 - Improving Candidate Retrieval with Entity Profile Generation for Wikidata Entity Linking (ACL)
Entity-based
- Wang+'22 - Towards Few-shot Entity Recognition in Document Images: A Label-aware Sequence-to-Sequence Framework (ACL) [arXiv
- Jeon+'22 - Entity-based Neural Local Coherence Modeling (ACL)
- Maddela+'22 - EntSUM: A Data Set for Entity-Centric Extractive Summarization (ACL)
- Barba+'22 - ExtEnD: Extractive Entity Disambiguation (ACL)
- Zhang+'22 - Modeling Temporal-Modal Entity Graph for Procedural Multimodal Machine Comprehension (ACL)
- Ye+'22 - Packed Levitated Marker for Entity and Relation Extraction (ACL)
- Li+'22 - Rethinking Negative Sampling for Handling Missing Entity Annotations (ACL)
- Ye+'22 - A Simple but Effective Pluggable Entity Lookup Table for Pre-trained Language Models (ACL)
- Jawahar+'22 - Automatic Detection of Entity-Manipulated Text using Factual Knowledge (ACL)
- Luo+'22 - An Accurate Unsupervised Method for Joint Entity Alignment and Dangling Entity Detection (ACL)
- Guo+'22 - Deep Reinforcement Learning for Entity Alignment (ACL)
- Wang+'22 - Towards Few-shot Entity Recognition in Document Images: A Label-aware Sequence-to-Sequence Framework (ACL)
Sentiment Analysis
ABSA
- Chen+'22 - Discrete Opinion Tree Induction for Aspect-based Sentiment Analysis (ACL)
- Chen+'22 - Enhanced Multi-Channel Graph Convolutional Network for Aspect Sentiment Triplet Extraction (ACL)
- Ling+'22 - Vision-Language Pre-Training for Multimodal Aspect-Based Sentiment Analysis (ACL)
- Zhang+'22 - Towards Unifying the Label Space for Aspect- and Sentence-based Sentiment Analysis (ACL)
- Liang+'22 - BiSyn-GAT+: Bi-Syntax Aware Graph Attention Network for Aspect-based Sentiment Analysis (ACL)
- Zhang+'22 - Incorporating Dynamic Semantics into Pre-Trained Language Model for Aspect-based Sentiment Analysis (ACL)
- Zhang+'22 - Towards Unifying the Label Space for Aspect- and Sentence-based Sentiment Analysis (ACL)
Others
- Wu+'22 - Adversarial Soft Prompt Tuning for Cross-Domain Sentiment Analysis (ACL)
- Shi+'22 - Effective Token Graph Modeling using a Novel Labeling Strategy for Structured Sentiment Analysis (ACL)
- Liang+'22 - MSCTD: A Multimodal Sentiment Chat Translation Dataset (ACL)
- Samuel+'22 - Direct parsing to sentiment graphs (ACL)
- Mao+'22 - M-SENA: An Integrated Platform for Multimodal Sentiment Analysis (ACL)
- Xing+'22 - DARER: Dual-task Temporal Relational Recurrent Reasoning Network for Joint Dialog Sentiment Classification and Act Recognition (ACL)
- Wu+'22 - Sentiment Word Aware Multimodal Refinement for Multimodal Sentiment Analysis with ASR Errors (ACL)
- Mao+'22 - Seq2Path: Generating Sentiment Tuples as Paths of a Tree (ACL)
- Ghazarian+'22 - What is wrong with you?: Leveraging User Sentiment for Automatic Dialog Evaluation (ACL)
- Nguyen+'22 - Improving the Generalizability of Depression Detection by Leveraging Clinical Questionnaires (ACL)
QA (retrieval)
Open-Domain QA / Retrieval
- Shao+'22 - Answering Open-Domain Multi-Answer Questions via a Recall-then-Verify Framework (ACL)
- Hagen+'22 - Clickbait Spoiling via Question Answering and Passage Retrieval (ACL)
- Zhou+'22 - Hyperlink-induced Pre-training for Passage Retrieval in Open-domain Question Answering (ACL)
- Yu+'22 - KG-FiD: Infusing Knowledge Graph in Fusion-in-Decoder for Open-Domain Question Answering (ACL)
- Ma+'22 - Open Domain Question Answering with A Unified Knowledge Interface (ACL)
- Zhang+'22 - Subgraph Retrieval Enhanced Model for Multi-hop Knowledge Base Question Answering (ACL)
- Liu+'22 - A Copy-Augmented Generative Model for Open-Domain Question Answering (ACL)
- Yue+'22 - C-MORE: Pretraining to Answer Open-Domain Questions by Consulting Millions of References (ACL)
- Jia+'22 - Question Answering Infused Pre-training of General-Purpose Contextualized Representations (ACL)
- Seonwoo+'22 - Two-Step Question Retrieval for Open-Domain QA (ACL)
- Louis+'22 - A Statutory Article Retrieval Dataset in French (ACL)
- Zheng+'22 - Cross-Lingual Phrase Retrieval (ACL)
- Krojer+'22 - Image Retrieval from Contextual Descriptions (ACL)
- Subramanian+'22 - ReCLIP: A Strong Zero-Shot Baseline for Referring Expression Comprehension (ACL)
- Zhang+'22 - Multi-View Document Representation Learning for Open-Domain Dense Retrieval (ACL)
- Lu+'22 - ReACC: A Retrieval-Augmented Code Completion Framework (ACL)
- Hong+'22 - Sentence-aware Contrastive Learning for Open-Domain Passage Retrieval (ACL)
- Gao+'22 - Unsupervised Corpus Aware Language Model Pre-training for Dense Passage Retrieval (ACL)
- Jeong+'22 - Augmenting Document Representations for Dense Retrieval with Interpolation and Perturbation (ACL)
- Xu+'22 - LaPraDoR: Unsupervised Pretrained Dense Retriever for Zero-Shot Text Retrieval (ACL)
- Niu+'22 - OneAligner: Zero-shot Cross-lingual Transfer with One Rich-Resource Language Pair for Low-Resource Sentence Retrieval (ACL)
- Xin+'22 - Zero-Shot Dense Retrieval with Momentum Adversarial Domain Invariant Representations (ACL)
- Zhao+'22 - Compressing Sentence Representation for Semantic Retrieval via Homomorphic Projective Distillation (ACL)
Question Generation
- Fei+'22 - CQG: A Simple and Effective Controlled Generation Framework for Multi-hop Question Generation (ACL)
- Zhao+'22 - Educational Question Generation of Children Storybooks via Question Type Distribution Learning and Event-centric Summarization (ACL)
- Cheng+'22 - HiTab: A Hierarchical Table Dataset for Question Answering and Natural Language Generation (ACL)
- Yao+'22 - It is AI’s Turn to Ask Humans a Question: Question-Answer Pair Generation for Children's Story Books (ACL)
- Ye+'22 - RNG-KBQA: Generation Augmented Iterative Ranking for Knowledge Base Question Answering (ACL)
- Berre+'22 - Unsupervised multiple-choice question generation for out-of-domain Q&A fine-tuning (ACL)
- Parrish+'22 - BBQ: A hand-built bias benchmark for question answering (ACL)
- Ghanem+'22 - Question Generation for Reading Comprehension Assessment by Modeling How and What to Ask (ACL)
- Dugan+'22 - A Feasibility Study of Answer-Unaware Question Generation for Education (ACL)
- Paranjape+'22 - Retrieval-guided Counterfactual Generation for QA (ACL)
MRC / Clozed-book
- Kumar+'22 - Answer-level Calibration for Free-form Multiple Choice Question Answering (ACL)
- Xu+'22 - How Do We Answer Complex Questions: Discourse Structure of Long-form Answers (ACL)
- Sugawara+'22 - What Makes Reading Comprehension Questions Difficult? (ACL)
- SU+'22 - Read before Generate! Faithful Long Form Question Answering with Machine Reading (ACL)
VQA
- Heo+'22 - Hypergraph Transformer: Weakly-Supervised Multi-hop Reasoning for Knowledge-based Visual Question Answering (ACL)
- Li+'22 - MMCoQA: Conversational Question Answering over Text, Tables, and Images (ACL)
- Masry+'22 - ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning (ACL)
- Qi+'22 - DuReader_vis: A Chinese Dataset for Open-domain Document Visual Question Answering (ACL)
- Pfeiffer+'22 - xGQA: Cross-Lingual Visual Question Answering (ACL)
Others
- Svikhnushina+'22 - A Taxonomy of Empathetic Questions in Social Dialogs (ACL)
- Li+'22 - Ditch the Gold Standard: Re-evaluating Conversational Question Answering (ACL)
- Xu+'22 - Fantastic Questions and Where to Find Them: FairytaleQA -- An Authentic Dataset for Narrative Comprehension (ACL)
- Shang+'22 - Improving Time Sensitivity for Question Answering over Temporal Knowledge Graphs (ACL)
- Li+'22 - KaFSP: Knowledge-Aware Fuzzy Semantic Parsing for Conversational Question Answering over a Large-Scale Knowledge Base (ACL)
- Cao+'22 - KQA Pro: A Dataset with Explicit Compositional Programs for Complex Question Answering over Knowledge Base (ACL)
- Yavuz+'22 - Modeling Multi-hop Question Answering as Single Sequence Prediction (ACL)
- Ye+'22 - On the Robustness of Question Rewriting Systems to Questions of Varying Hardness (ACL)
- Cao+'22 - Program Transfer for Answering Complex Questions over Knowledge Bases (ACL)
- Wu+'22 - QAConv: Question Answering on Informative Conversations (ACL)
- Saxena+'22 - Sequence-to-Sequence Knowledge Graph Completion and Question Answering (ACL)
- Gao+'22 - Simulating Bandit Learning from User Feedback for Extractive Question Answering (ACL)
- Yue+'22 - Synthetic Question Value Estimation for Domain Adaptation of Question Answering (ACL)
- Byrd+'22 - Predicting Difficulty and Discrimination of Natural Language Questions (ACL)
- Baumgartner+'22 - UKP-SQUARE: An Online Platform for Question Answering Research (ACL)
- Wang+'22 - Co-VQA : Answering by Interactive Sub Question Sequence (ACL)
- ZHANG+'22 - Fact-Tree Reasoning for N-ary Question Answering over Knowledge Graphs (ACL)
- Zhao+'22 - Implicit Relation Linking for Question Answering over Knowledge Graph (ACL)
- Li+'22 - Using Interactive Feedback to Improve the Accuracy and Explainability of Question Answering Systems Post-Deployment (ACL)
- Deutsch+'22 - Benchmarking Answer Verification Methods for Question Answering-Based Summarization Evaluation Metrics (ACL)
Web
ParlAI で画像+対話モデル(Multi-Modal BlenderBot)を動かすための手順
- 実際に学習したモデルを使用して推論(デモ)した結果等については、順次追記していきます。
- 本ページでは、Multi-Modal BlenderBot を学習してみたい人に向けて、その概要を紹介します(スクリプトの詳細な説明などについてはドキュメント等を参照ください)。

目次
本編の前に
ParlAI とは
Multi-Modal BlenderBot とは
Shuster+'21 - Multi-Modal Open-Domain Dialogue (EMNLP) [ACL Anthology][arXiv][ParlAI Project](クリックで論文概要を開く)
1. どんなもの?
- 対話モデルと画像認識モデルを統合したマルチモーダル対話モデルの提案
2. 先行研究と比べてどこがすごい?
- 複数ターンによる雑談対話 + 既存のマルチモーダル対話(キャプション生成や VQA ベース)に比べて優れた対話性能
- テキストベースの会話においても BlenderBot と同等の性能
- 不快感を与えないための safety component を組み込む(画像+対話の分野ではあまり調査されていない)
3. 技術や手法のキモはどこ?
Transformer ベースの seq2seq モデルに対して、事前学習済み ResNeXt / Faster R-CNN ベースの画像エンコーダから取得した視覚表現を統合するために early-/late- fusion という二つの手法を提案。なお画像エンコーダは線形層のみ学習を行う。
pre-training / fine-tuning の枠組みで Transformer(2.7B パラメータ / 2 enc - 24 dec / 2560 dim / 32 attn heads) を学習:
| pt/ft | データセット | サイズ | 概要 |
|---|---|---|---|
| pre-training | 1.5B | Reddit のリプライチェーン(テキストデータ) | |
| domain-adaptive pre-training | 同上 | ||
| domain-adaptive pre-training | COCO Captions | 600K | キャプション生成 |
| fine-tuning | ConvAI2 | 140K | ペルソナ + 対話データ |
| fine-tuning | EmpatheticDialogues | 50K | 共感 + 対話データ |
| fine-tuning | Wizard of Wikipedia | 194K | 知識 + 対話データ |
| fine-tuning | BlendedSkillTalk | 74K | 三つのブレンド + 対話データ |
| fine-tuning | Image-Chat | 400K | 画像 + スタイル(性格) + 対話 |
4. どうやって有効だと検証した?
BlenderBot / DialoGPT / Meena, dodecaDialogue / 2AMMC と比較

テキスト対話

マルチモーダル対話:ACUTE-Eval に基づく人手評価

5. 議論はある?
6. 次に読むべき論文は?
- Roller+'20 - Recipes for building an open-domain chatbot [arXiv]
- Shuster+'20 - The Dialogue Dodecathlon: Open-Domain Knowledge and Image Grounded Conversational Agents (ACL) [arXiv]
Multi-Modal BlenderBot を動かす
ParlAI の導入
$ git clone git@github.com:facebookresearch/ParlAI.git -b v1.5.1
$ cd ParlAI
# 仮想環境構築(適当な構築方法を選択)
$ conda create -n {envname} python=3.9 -y
$ pyenv local {envname}
$ pip install -e .
学習済みモデルパラメータの取得
- 学習済みのモデルパラメータを取得するためには、Google Form に回答する必要がある。
Due to safety concerns, we are only releasing model weights by request. Please fill out this form to request access to a time-limited link to download model weights. We will grant access only to members of university or corporate research labs, for research use only. Please provide links to one or more of your previously published papers to aid in acceptance of your request. ParlAI/README.md at main · facebookresearch/ParlAI · GitHub
学習スクリプト
学習時の実行コードについては、以下を参照: github.com
上記のリンクでは、domain-adaptive pre-training の引数を以下のように指定している:
# `parlai tm` は `python parlai/scripts/train_model.py` と同義 parlai tm \ -t coco_caption \ # TeacherAgent --include-rest-val True \ --include-image-token False \ --activation gelu \ --attention-dropout 0.0 \ --batchsize 128 \ --dropout 0.1 \ --fp16 True \ --gradient-clip 0.1 \ --label-truncate 128 \ --log-every-n-secs 30 \ --lr-scheduler reduceonplateau \ --max-train-time 169344.0 \ --model-parallel True \ --model image_seq2seq \ # StudentAgent --init-model zoo:blender/reddit_3B/model \ # 初期パラメータ --dict-file zoo:blender/reddit_3B/model.dict \ # 辞書ファイル --embedding-size 2560 \ --ffn-size 10240 \ --n-decoder-layers 24 \ --n-encoder-layers 2 \ --n-heads 32 \ --n-positions 128 \ --variant prelayernorm \ --text-truncate 128 \ --truncate 128 \ --dict-tokenizer bytelevelbpe \ --fp16-impl mem_efficient \ --optimizer adam \ --update-freq 2 \ --history-add-global-end-token end \ --delimiter ' ' \ --lr-scheduler-patience 3 \ --warmup-updates 100 \ --multitask-weights 1,1 \ --relu-dropout 0.0 \ --save-after-valid True \ --skip-generation True \ -lr 7e-06 \ -vtim 1800 \ -vmm min \ -vmt ppl \ -vp 10 \ -vme 24000 \ --image-fusion-type early \ # early-fusion (or late) --n-segments 2 \ --n-image-channels 100 \ --model-file ${DOMAIN_PRETRAINED_MODEL_PATH} # 保存先
TeacherAgent (DataLoader)
- https://www.parl.ai/docs/core/teachers.html
ParlAI の 実行コマンド では
--task (-t)で使用する TeacherAgent (DataLoader) を指定する。- 上記の domain-adaptive pre-training 実行コマンドでは、
-t coco_captionを指定しており、COCO Captions の TeacherAgent を使用している。
StudentAgent (Model)
上記の domain-adaptive pre-training 実行コマンドでは、
--model image_seq2seqを指定している:- https://github.com/facebookresearch/ParlAI/blob/main/parlai/agents/image_seq2seq/modules.py#L236-L241
forwardメソッド内部で、early-fusion / late-fusion の分岐を行う。
Interactive
Chen+'21 - Salient Phrase Aware Dense Retrieval - Can a Dense Retriever Imitate a Sparse One?
https://arxiv.org/abs/2110.06918
1. どんなもの?
- TF-IDF のような疎ベクトル表現では、レア単語や高い顕現性を持つ単語のマッチングに対して効果的であり、ドメイン外への一般化も優れる。一方で、密なベクトル表現を用いたマッチング手法ではこれらに対して汎化することが難しい。そこでスパースモデルで作成した正例・負例データから DPR を学習する Salient Phrase Aware Retriever (SPAR) を提案。MS MARCO の検索ベンチマークや、BEIR などのを含む五つの質問応答データで SoTA と同等以上の検索性能を達成。
2. 先行研究と比べてどこがすごい?
- DR では vocabulary mismatch(同じ意味で違う語)や semantic mismatch(同じ語で違う意味)などに対して効果的である一方、高い顕現性を持つフレーズに対してマッチしない場合やドメイン外の評価タスクに対して汎化性能が低い場合がある。
- DeepImpact のような密→疎のモデル化は様々な取り組みが行われていたが、逆のアプローチはほとんどない。
3. 技術や手法のキモはどこ?

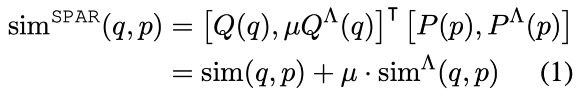
- DPR モデルに加えて、BM25 によって作成した文書ペアを用いて学習された SPAR (DPR-based) を用いる。SPAR を学習するための正例・負例データは、BM25 を用いて上下*件を使用する。
- MSE や KL-div に基づいた疎ベクトル表現の組み込みオプションが考えられるが、あまり効果が得られなかった。
4. どうやって有効だと検証した?



SPAR の有効性検証

- Natural Questions を用いて学習 + acc@20, acc@100 で評価。
- SPAR の出力ベクトルを用いて DPR を学習(Joint Training)しても性能は良くない。
- ベクトル連結(Weighted Concat)では、2 DPRs と比較すると性能が改善したことから、SPAR の効果が検証された。
- ただベクトルの次元数は増えるので検索コストは大きくなる(保持するのであればキツい?)。
5. 議論はある?
本研究の設定において正例の数を増やすと大幅に性能が改善したことから、負例だけでなく正例の作成も必要(本研究では正例数を 10、負例数を 5 で実験)。

データサイズもかなり検索性能に影響。

2 DPRs で検索性能が低下しているが、異なるタスクごとに DPR を学習して,推論結果を集約すると性能が改善される研究も存在。いずれにせよモデルパラメータが増えるのが難点...
- Li+'21 - Multi-Task Dense Retrieval via Model Uncertainty Fusion for Open-Domain Question Answering (EMNLP) [ACL Anthology][GitHub]
SPAR に BM25 を追加するとゲインが少ない。BM25 とのアンサンブルの方がメモリ使用量が少なくて済む可能性があるかもしれない?

6. 次に読むべき論文は?
- Karpukhin+'20 - Dense Passage Retrieval for Open-Domain Question Answering (EMNLP)
Luo+'22 - Choose Your QA Model Wisely: A Systematic Study of Generative and Extractive Readers for Question Answering
https://arxiv.org/abs/2110.06393
1. どんなもの?
- QA タスクで用いられる reader において生成型・抽出型の比較。
2. 先行研究と比べてどこがすごい?
3. 技術や手法のキモはどこ?

抽出型 Reader
- 質問・文書のトークンを入力とし、解答のスパンを抽出する。二層の線形層を用いる。

- 二種類のモデルを使用:
生成型 Reader
- 解答を直接生成。推論時は貪欲探索。

4. どうやって有効だと検証した?
評価データと文書長ヒストグラム




その他の実験設定
- 4.3 節 / Appendix.B に実験設定あり。
- 入力形式:
- 抽出型 reader:
{Q [SEP] C} - 生成型 reader:
{question: Q [SEP] context: C}
- 抽出型 reader:
- 生成モデルにおける max_length は 16(性能差はほとんどない)

文書長に対する効果
- seq_max_length を 512 で学習、推論時は表にある三種類。ドメイン内外において、それぞれの平均値を記載(Tab.10-12 に詳細あり)。

アーキテクチャ比較
抽出型 reader 同士の比較:E-Extractive v.s. ED-Extractive
- 抽出型 reader においては、decoder がほとんど性能に寄与しない。BART では不要、T5 では若干の性能改善があるが、モデルパラメータ数を鑑みると不要っぽい。

Enc-Dec における抽出型・生成型の比較:ED-Extractive v.s. ED-Generative
- モデルパラメータサイズは同等。single-task / multi-task (OOD) における BART を除いて、生成型モデルが良い性能。

E-Extractive v.s. ED-Generative
- T5 では生成型モデルが優勢(抽出型モデルはパラメータ数が少ない)。一方で BART では抽出型モデルが優勢。

モデル比較 (WIP)

入力長 (WIP)

低頻度語
- 低頻度語に対しては抽出型 reader が効果的。生成型モデルを使用する場合は、Answer Post-Processing が必要になりそう。
- 特に T5 では低頻度語が
<unk>になってしまうことが性能悪化の原因。
5. 議論はある?
- T5, BART の生成型・抽出型における性能差は、事前学習タスクに依存している?
- 各モデルの解答傾向(アンサンブルの結果)が気になる。
- T5 の
<unk>問題については、拡張法(第二回 AI 王で ICS Lab. チームがやっていたようなトークナイズにおける複数パターンのトークンを用いる工夫が有効そう) - Zhu+'21 - Retrieving and Reading: A Comprehensive Survey on Open-domain Question Answering では、抽出型 reader をさらに二つのタイプで分類している(検索した関連文書を独立・共同で処理)。
6. 次に読むべき論文は?
Cheng+'21 - UnitedQA: A Hybrid Approach for Open Domain Question Answering (ACL/IJCNLP) [ACL Anthology][arXiv]
Zhu+'21 - Retrieving and Reading: A Comprehensive Survey on Open-domain Question Answering
Ni+'21 - Large Dual Encoders Are Generalizable Retrievers [arXiv]
Izacard+'20 - Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering (EACL) [ACL Anthology][arXiv][GitHub]