Chen+'21 - Salient Phrase Aware Dense Retrieval - Can a Dense Retriever Imitate a Sparse One?
https://arxiv.org/abs/2110.06918
1. どんなもの?
- TF-IDF のような疎ベクトル表現では、レア単語や高い顕現性を持つ単語のマッチングに対して効果的であり、ドメイン外への一般化も優れる。一方で、密なベクトル表現を用いたマッチング手法ではこれらに対して汎化することが難しい。そこでスパースモデルで作成した正例・負例データから DPR を学習する Salient Phrase Aware Retriever (SPAR) を提案。MS MARCO の検索ベンチマークや、BEIR などのを含む五つの質問応答データで SoTA と同等以上の検索性能を達成。
2. 先行研究と比べてどこがすごい?
- DR では vocabulary mismatch(同じ意味で違う語)や semantic mismatch(同じ語で違う意味)などに対して効果的である一方、高い顕現性を持つフレーズに対してマッチしない場合やドメイン外の評価タスクに対して汎化性能が低い場合がある。
- DeepImpact のような密→疎のモデル化は様々な取り組みが行われていたが、逆のアプローチはほとんどない。
3. 技術や手法のキモはどこ?

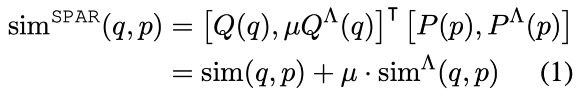
- DPR モデルに加えて、BM25 によって作成した文書ペアを用いて学習された SPAR (DPR-based) を用いる。SPAR を学習するための正例・負例データは、BM25 を用いて上下*件を使用する。
- MSE や KL-div に基づいた疎ベクトル表現の組み込みオプションが考えられるが、あまり効果が得られなかった。
4. どうやって有効だと検証した?



SPAR の有効性検証

- Natural Questions を用いて学習 + acc@20, acc@100 で評価。
- SPAR の出力ベクトルを用いて DPR を学習(Joint Training)しても性能は良くない。
- ベクトル連結(Weighted Concat)では、2 DPRs と比較すると性能が改善したことから、SPAR の効果が検証された。
- ただベクトルの次元数は増えるので検索コストは大きくなる(保持するのであればキツい?)。
5. 議論はある?
本研究の設定において正例の数を増やすと大幅に性能が改善したことから、負例だけでなく正例の作成も必要(本研究では正例数を 10、負例数を 5 で実験)。

データサイズもかなり検索性能に影響。

2 DPRs で検索性能が低下しているが、異なるタスクごとに DPR を学習して,推論結果を集約すると性能が改善される研究も存在。いずれにせよモデルパラメータが増えるのが難点...
- Li+'21 - Multi-Task Dense Retrieval via Model Uncertainty Fusion for Open-Domain Question Answering (EMNLP) [ACL Anthology][GitHub]
SPAR に BM25 を追加するとゲインが少ない。BM25 とのアンサンブルの方がメモリ使用量が少なくて済む可能性があるかもしれない?

6. 次に読むべき論文は?
- Karpukhin+'20 - Dense Passage Retrieval for Open-Domain Question Answering (EMNLP)