Oguz+'22 - UniK-QA: Unified Representations of Structured and Unstructured Knowledge for Open-Domain Question Answering (NAACL-HLT)
1. どんなもの?
- オープンドメイン質問応答において、様々な知識ソース(テキスト、表、リスト、KB)を扱うための統合手法を提案。
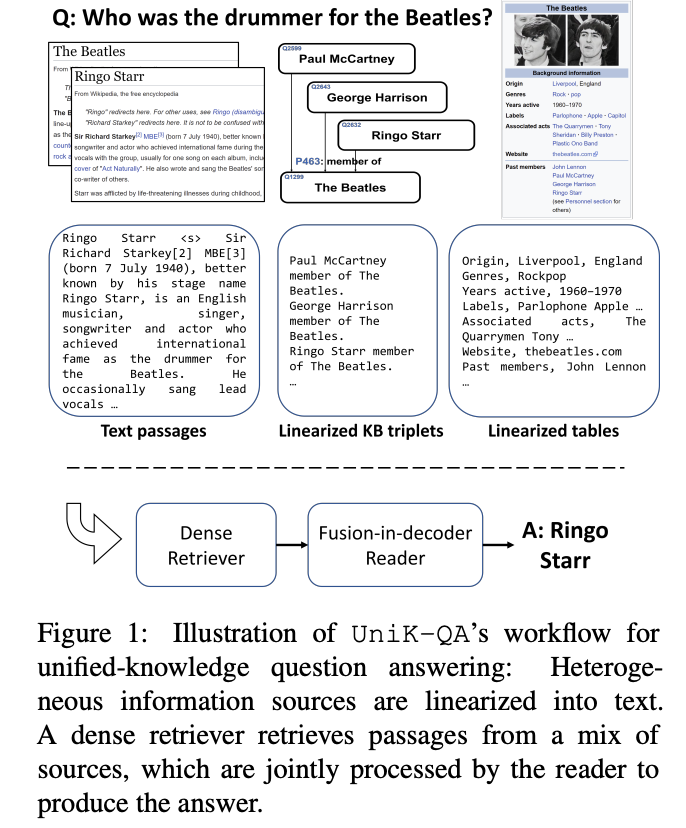
- KBQA タスクで大幅な性能改善、NQ・WebQuestions で SoTA を達成。
2. 先行研究と比べてどこがすごい?
- 先行研究では (1) 構造化知識ベースを用いた KBQA、および (2) テキストベースにおけるオープンドメイン質問応答タスク TextQA を別タスクとすることが一般的。テキストを知識グラフに組み込む手法 (Sun+'18; Lu+'19)も研究されているが、性能はあまり良くない。
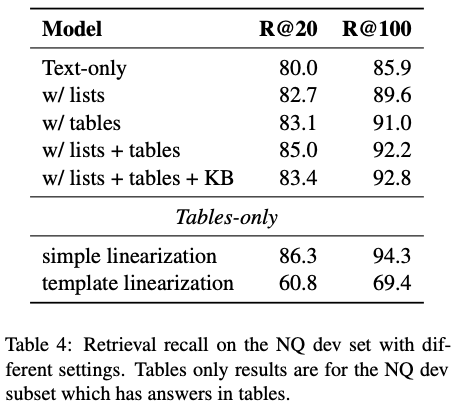
- 本研究では、複数のサブシステムを保有したり、テキストを知識グラフに組み込んだりするのではなく、構造データをテキスト形式に変換することで構造化データを Transformer を用いた retriever-reader (DPR-FiD) 型システムで扱えるようにする。
- テキストやリストから構成される 27M の文書 + 456K の Wikipedia テーブル + Freebase および Wikidata から取得される 3B の知識ベース
3. 技術や手法のキモはどこ?
3.1. UniK-QA
- retriever-reader (DPR-FiD) システムを使用
- DPR 学習時は、Xiong+'21 のようにハード負例を学習ステップごとに選択する
- FiD では T5-large を用い、100 文書から解答を生成する
3.2. 知識ベースの統合
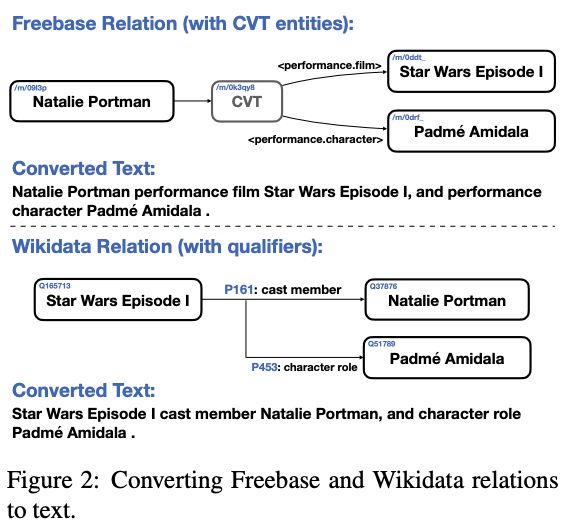
- RDF triple を
[subj] [pred] [obj]の形で変換するtemplate-based linearization:数十万種類の関係に対してテンプレートを用意するのは高コストmodel-based linearization:学習コストが加算 + 検索の再現性が低くなる
- 数十億単位の KB 全体をインデックス化することを回避するために、関係の検索を二段階で実装:
3.3. リスト・テーブルの統合
- リストについては、単にテキスト文書の一部として保持(することで検索性能が向上)
- テーブル(表+info-boxes)は NQ データが取得したものを使用し、入れ子テーブルは独立単位に抽出、また一行の表および
service表を除去。 - テーブルは以下二種類でテキスト化:
4. どうやって有効だと検証した?